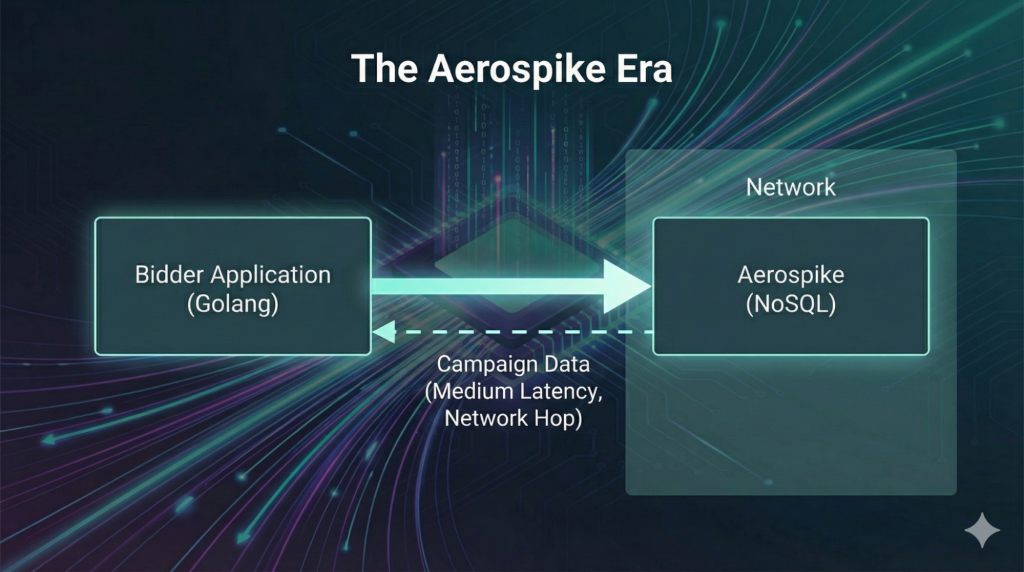
Phase 1: The Aerospike Era
To solve the latency crisis, we evaluated several tech stacks and landed on Aerospike.
Aerospike is a beast when it comes to speed and high throughput. By migrating our data to this NoSQL solution, we saw immediate results. We eliminated the overhead of SQL and reduced our internal lookup latency to a fluctuation of 4ms to 6ms.
For a while, this was sufficient. We were handling higher QPS, and the system was stable. But in engineering, “stable” is just a temporary state before the next scale-up.
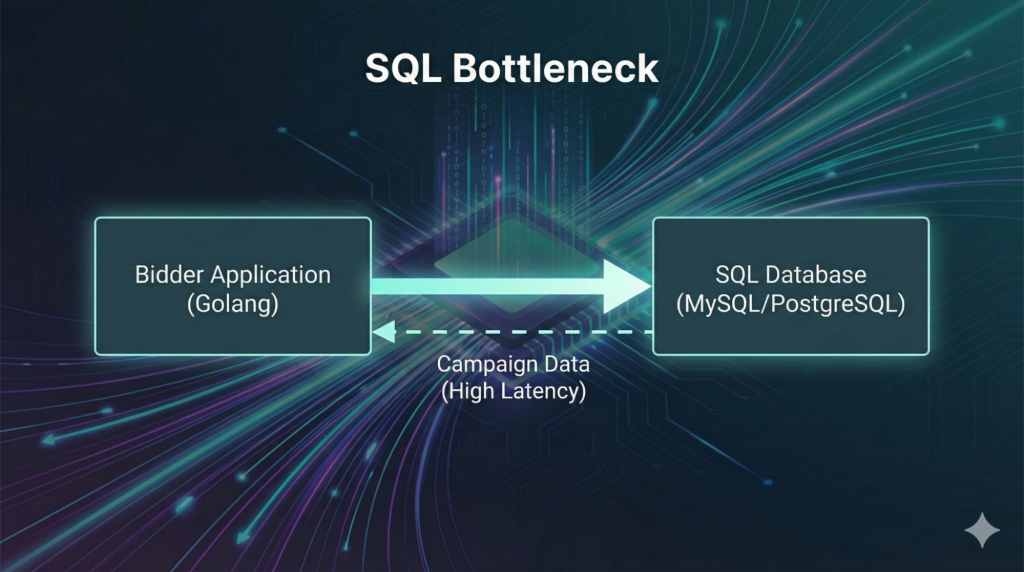
The Hidden Cost of Network I/O
As we aimed to scale up further to handle massive global traffic, we noticed a new bottleneck. While 4ms is fast, it involves a network hop.
When you are processing hundreds of thousands of requests per second, even a tiny amount of network latency compounds. Every time our software had to reach out to Aerospike over the network, it introduced a wait time. At high concurrency, these tiny waits led to increased CPU usage as the system managed thousands of open connections and context switches.
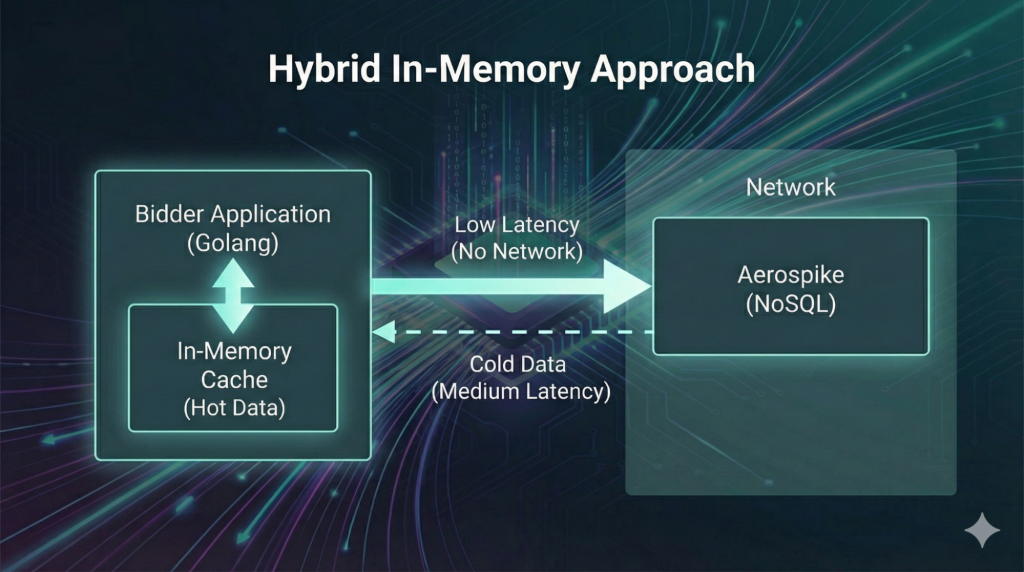
We realized that to process more QPS with the same hardware, we had to stop crossing the network for every single decision.

Post Comment